Public Housing Demand in Johannesburg
Millions of people move to Johannesburg every year in search of opportunities, yet the housing market is not able to keep up with demand. The government’s Department of Human Settlements has various housing programs in all municipalities such as Johannesburg to provide housing subsidies to citizens. A housing subsidy is a once-off grant paid by the government to qualifying beneficiaries for housing purposes. The grant is not paid in cash to beneficiaries but, rather, is paid to the seller of a house or, in new subsidised housing developments, the grant is used to construct a house. The title deed of the constructed house is then registered in the name of the beneficiary.
This project explores the housing subsidy applicant data for citizens in the City of Johannesburg which stood at approximately 450,000 applicants in 2018.
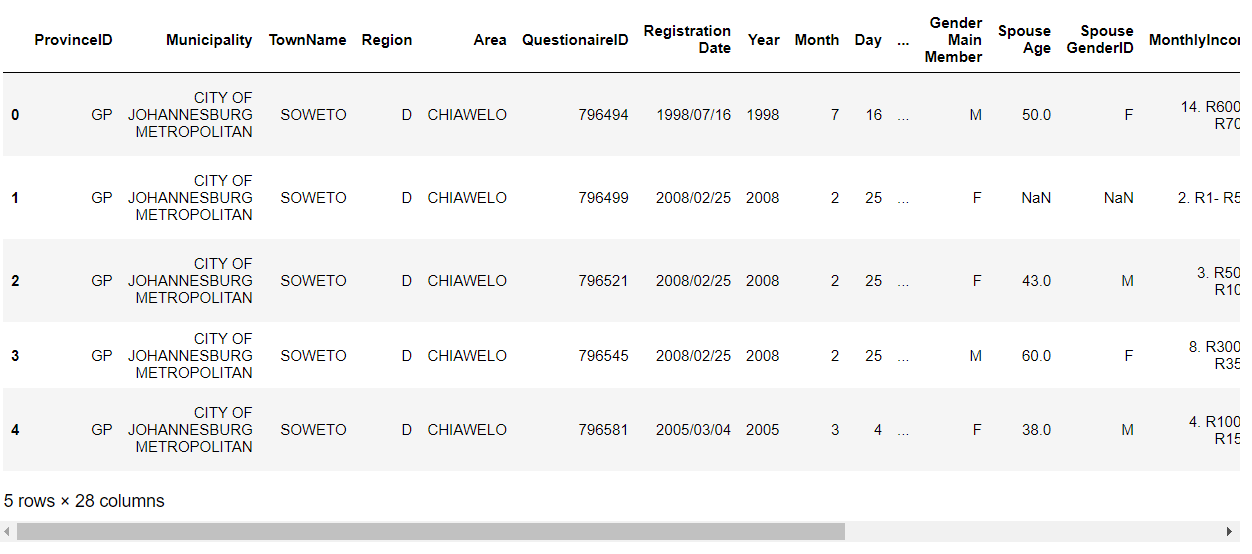
This page is split into two sections, Insights and Data Cleaning - and covers 5 insights I extracted from the dataset and also 5 things I did to clean the dataset and improve data quality. I have included snippets of the Python code used in my analysis and made use of the Seaborn library and Tableau to create data visulisations.
Insights
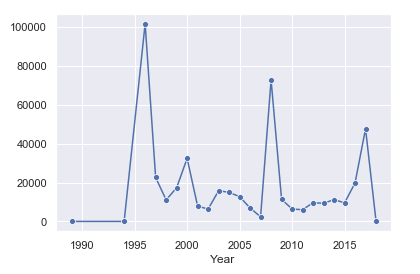
1. Number of housing applications made from 1994 to 2018
- Apart from the initial spike when the housing program was launched, the top 3 years for housing applications were:
- 2008 (72,755 applications)
- 2017 (47,642 applications)
- 2000 (32,408 applications)
- The average number of applications over this period was 17,622.
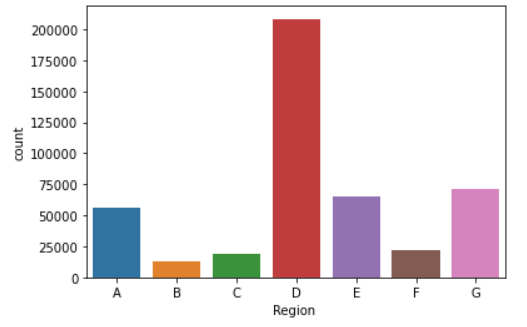
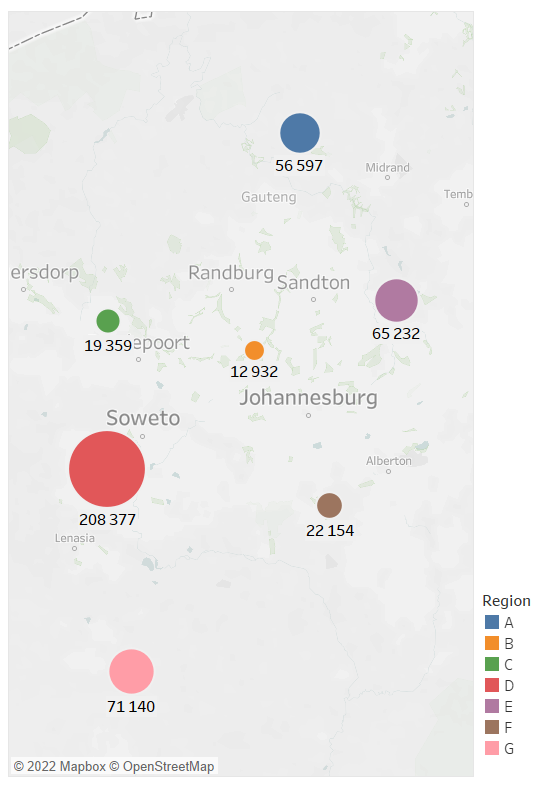
2. Distribution of applicants across each region of Johannesburg
- Region D has the most applicants. Soweto is located in Region D which is one of the most populated areas in Johannesburg. Soweto alone is home to 1.2 million people out of Johannesburg’s 5.6 million population.
sns.countplot(x=newdf['Region '], order=['A','B','C','D','E','F','G'])
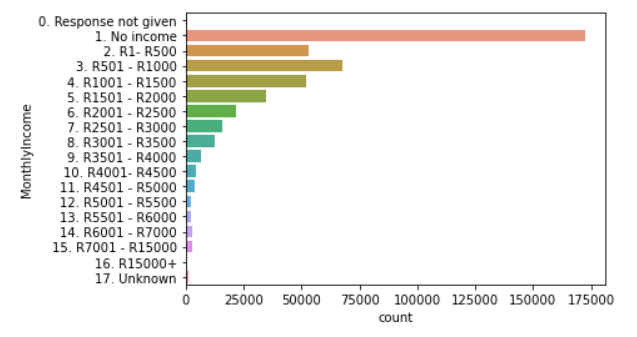
3. Monthly income distribution of applicants:
- One of the qualifying criteria an applicant has to meet in order to receive a housing subsidy is to have an income below R3500.
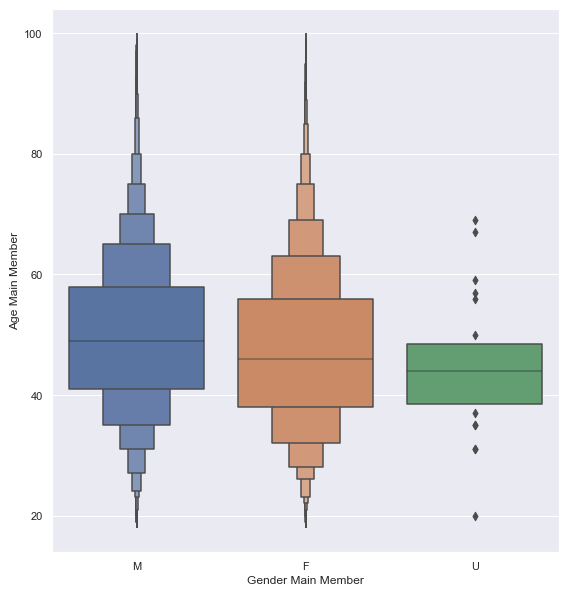
4. Age distribution of applicants split by gender.
- M = Male, F = Female, U = Unknown
- The average age of male applicants is 49 years old.
- The average age of female applicants is 47 years old.
- There are more female applicants than male applicants (25,310 vs 20,2810)
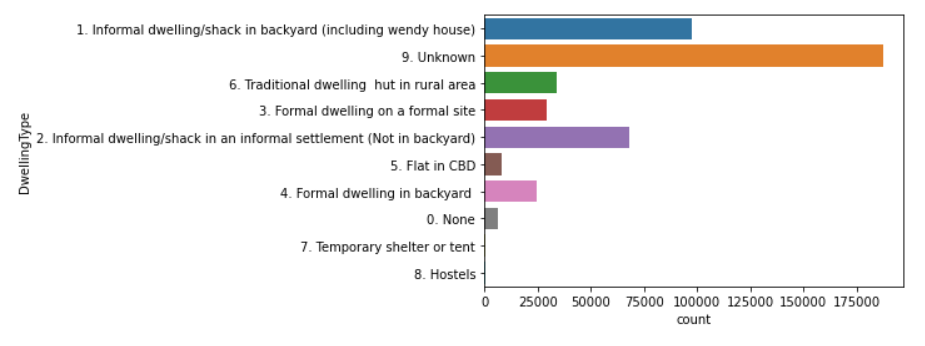
5. Current dwelling types of applicants.
- Most applicants for public housing are those living in informal dwelling types and likely have poor access to water, energy and sanitation services.
Data Cleaning
Below is a breakdown of how I explored and cleaned the public housing applicant dataset.
Here is a summary of rows that have data in each column and as we can see several columns have data gaps where no values were entered:
newdf.count()
ProvinceID 455791
Municipality 455791
TownName 455791
Region 455791
Area 455791
QuestionaireID 455791
Registration Date 455791
Year 455791
Month 455791
Day 455791
StreetName 454786
HouseNo 455498
WardNo 25097
HomeTelNo 216429
WorkTelNo 1843
CellNo 290476
Relationship 455791
Age Main Member 455388
Gender Main Member 455786
Spouse Age 36302
Spouse GenderID 36305
MonthlyIncome 455717
HSS Status 455791
DwellingType 455788
EnergySource 455788
Sanitation 455788
Water 455788
Disability 73683
dtype: int64
1. Removing duplicate data
- I identified duplicate entries based on the QuestionaireID field since each unique applicant should have a unique Questionnaire and only one entry in the applicant dataset.
- My analysis found 14,238 duplicates in the dataset which were removed and reduced the number of unique applicants to 441,553.
p = newdf.duplicated('QuestionaireID')
q = []
for i in p.iteritems():
if i[1] == True:
q.append(i[0])
len(q) = 14238
newdf.drop_duplicates(subset='QuestionaireID', keep='first',inplace=True)
2. Removing superfluous columns:
- Province and Municipality are the same for the whole dataset (“Gauteng” and “Johannesburg”)
- Work telephone number, spouse age and spouse gender were provided by very few applicants and will not be useful for analysis of the main applicant.
newdf = newdf.drop(columns=['ProvinceID','Municipality','WorkTelNo','Spouse Age', 'Spouse GenderID'])
3. Filling the gaps or empty rows:
- Here I filled null values with a more relevant value is not data was provided.
newdf['StreetName'] = newdf['StreetName'].fillna('None')
newdf['HouseNo'] = newdf['HouseNo'].fillna('None')
newdf['WardNo'] = newdf['WardNo'].fillna(0)
newdf['HomeTelNo'] = newdf['HomeTelNo'].fillna('None')
newdf['CellNo'] = newdf['CellNo'].fillna('None')
newdf['Age Main Member'] = newdf['Age Main Member'].fillna(0)
newdf['Gender Main Member'] = newdf['Gender Main Member'].fillna('U')
newdf['MonthlyIncome'] = newdf['MonthlyIncome'].fillna('0. Response not given')
newdf['DwellingType'] = newdf['DwellingType'].fillna('9. Unknown')
newdf['EnergySource'] = newdf['EnergySource'].fillna('9. Unknown')
newdf['Sanitation'] = newdf['Sanitation'].fillna('10. Unknown')
newdf['Water'] = newdf['Water'].fillna('12. Unknown')
4. Investigation of Ward number values:
- As shown by output below, I found that the Ward number column is filled with poorly formatted data, inconsistent data types and string values, where only integers are expected. The quality of the data would not be good enough to use in the analysis so I removed this column with a plan to rebuild it later.
newdf['WardNo'].unique()
array([0, '11', '2', '12', '121', '32', '23', '22', '21', '10', '1002',
'2003', '100', '200', '65', '95', '920', '632', '0', '62', '16',
'119', '25', '66', '29', '19', ' ', 'BLOCK 8', '47', '53', '48',
'63', '321', '500', '153', '85', '42', '43', '103', '1661', '654',
'129', '44', '45', '7', '50', 'none', '84', '49', '82', '52', '9',
12.0, 14.0, 24.0, 35.0, 32.0, 200.0, 100.0, 20.0, 65.0, 95.0, 50.0,
119.0, 53.0, 952.0, 129.0, 51.0, 61.0, 54.0, 31.0, 29.0, 30.0,
10.0, 15.0, 125.0, 123.0, 120.0, 21.0, 34.0, 28.0, 632.0, 652.0,
321.0, 62.0, 654.0, 39.0, 2003.0, 1002.0, 27.0, 621.0, 962.0,
332.0, 19.0, 26.0, 25.0, 122.0, 112.0, 236.0, 3176.0, 23.0, 2001.0,
52.0, 130.0, 110.0, '26', '33', '300', '231', '35', '621', '36',
'951', '37', '34', '652', '54', '6', '24', '46', '51', '1', '17',
'13', '55', '18', 'Q', '2127', '259', '41', '38', '39', '322',
'2000', '20', '98', '962', '130', '14', '40', '102', '8', '230',
'123', '1230', '522', '620', '191', 'NONE', '31', '120', '852',
'3', '202', '125', '563', '630', '5', '4', '56', '921', '15', '27',
'28', '30', '106', '227', '92', ' ', '362', 'WARD 25',
'REGION 9', 'MAPETLA', '952', '2001', '3003', '39/41', 'WARD 39',
'213', '963', '263', '210', 'ward 15', '122', 'EXT 29', '542',
'49FARANA', '127', '113', 'ward 12', '1003', '193', '320', '520',
'57', 'NUL', 'CHRIS HANI', '149', '201', '114', 'REGION D', '651',
'400', ' N/A', '258', 'PIMVILLE EXT6', 'kh', '4061A', '203', '115',
'135', 'NU', 'ZONE 6', '128', 'DIEPKLOOF ZONE 4', '199',
'PROTEA NORTH', 'PIMVILLE ZONE 4', '67', 'non', 'WARD 75',
' ', '107', '91', '90', '600', '521', '159', 'E', '75',
'no 15 avenue', '3002', 'REGION A', ']', 'REGION6', 'A', '352',
'156', '1159', '145', '221', '911', '960', '96', '116', '154',
'152', '69', '650', '124', '77', '60', '2111', '403', '68', '118',
'279', ' CAMP', '58', '965', 'van der merwe', '178', '1830', '126',
'627', '1811', 'fre', '24 FREEDOM PARK', 'AVENUE', '1376', '3597',
'STR', '59', 'WARD 62', '61', '1259', '86', 'WARD 60', 'NO', '610',
'73', 'WARD 21', '74', '2100', '79', '105', '196', '80', 'T',
'UNKOWN', '97', '1122', '89', '64', 'BLOCK A', 'unknoww',
'THABEDE', '110', 'GRASMERE', 'MOUNTAIN VIEW', 'G', 'unknown',
'832', 'PLOT 56', 'WARD 10', '241', '358', '829', '693', 'ext 9',
22.0, 1.0, 57.0, 89.0, 6.0, 7.0, 79.0, 111.0, 77.0, '2103', '192',
'78', 'mlilo', '08 REGION A', '111', '214', '177', 'RGION 4',
'131', 'EXT 3B', '2013', '1000', 'ward 3', '953', '99', '491',
'EXT2', '71', '70', '72', '925', '624', '914', '220', '81', '83'],
dtype=object)
5. Investigation of applicant Age values:
- As shown in the output above the highest age entered is 1814 and the lowest age is 0 indicating some data entry errors as these ages are unrealistic age values for an applicant and would skew the data.
- In order to remove these outliers, I removed rows from the dataset where the age value was under 18 or over 100. This resulted in the removal of 648 rows.
- Interestingly, there still appear to be some applicants where the age value is 100. This may be plausible but would require further investigation to ensure this is not a data error.
newdf['Age Main Member'].describe()
count 441553.000000
mean 48.312248
std 13.670387
min 0.000000
25% 39.000000
50% 47.000000
75% 57.000000
max 1814.000000
Name: Age Main Member, dtype: float64
newdf.drop(newdf[newdf['Age Main Member']>100].index, inplace=True)
newdf.drop(newdf[newdf['Age Main Member']<18].index, inplace=True)
newdf['Age Main Member'].describe()
count 440905.000000
mean 48.323522
std 13.204649
min 18.000000
25% 39.000000
50% 47.000000
75% 57.000000
max 100.000000
Name: Age Main Member, dtype: float64